
Dense vs. MoE: Understand the Differences
In the rapidly evolving of AI models, understanding the underlying architecture of language models is key to appreciating their capabilities and limitations. At the moment, two main approaches stand out: Dense Models and Mixture of Experts (MoE) Models. While both aim to deliver powerful AI, they take fundamentally different paths, each with its own set of advantages and catches.
Dense Models: The “Big Brain”
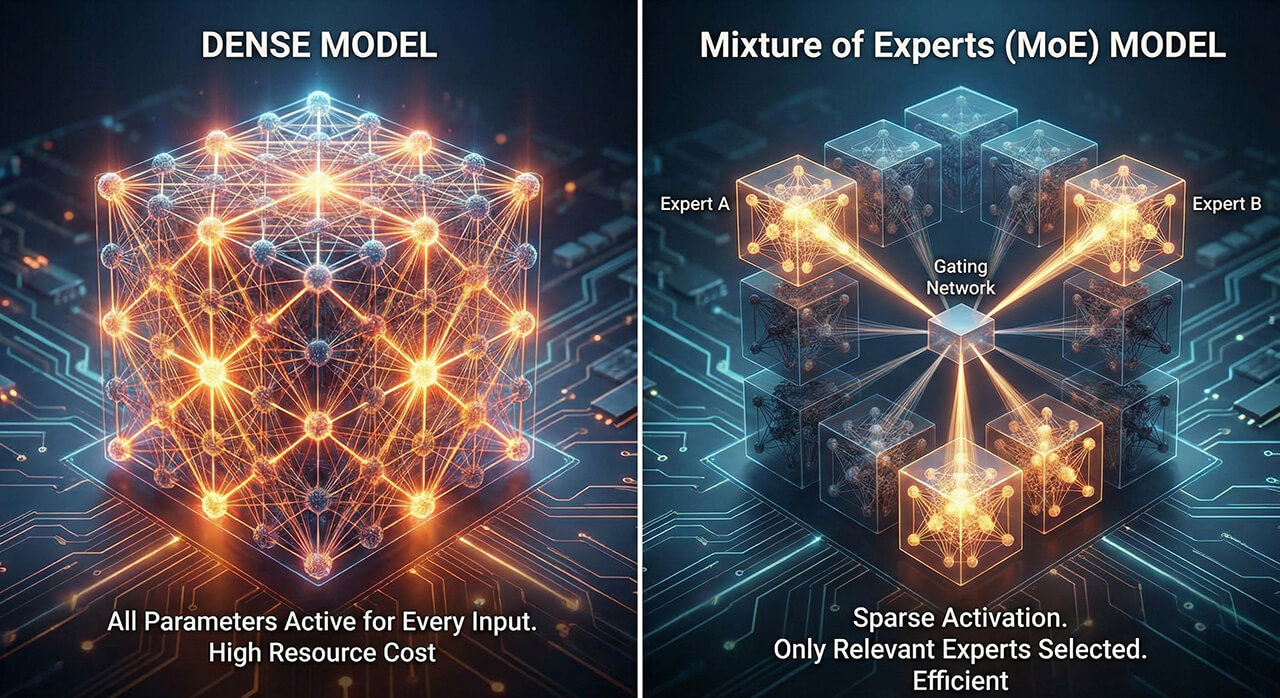
Imagine a dense model as a single, massive brain. When you pose a question or give a command, this entire brain (every single one of its parameters) activates and works together to process the information. If you ask a model that has 30B parameters about coding, it uses all of the 30B to answer, even the parts of model that are not related to coding.
It’s a “jack of all trades,” with its knowledge broadly distributed across its entire network.
Pros:
- Simplicity and Stability: Dense models are generally easier to design, train, and fine-tune. Their consistent architecture makes them very stable during training.
- Widespread Support: Being the traditional model, they often have better support for optimization techniques like quantization, making them easier to run on various hardware.
Cons:
- Scaling Tax: As dense models grow larger (more parameters to become smarter), they become proportionally slower and more expensive to run. Every parameter contributes to the computational cost of each inference (So if you can’t fit the entire model into GPU VRAM, it’s going to be very slow)
- Computational Intensity: Even for simple tasks, the entire network is engaged, which can be inefficient for very large models.
MoE Models: The “Committee of Specialists”
MoE model operates more like a committee. It consists of multiple expert sub-networks. Each specializing in different types of tasks or data (Coding, Cooking, Chemistry, History, etc.). Only parameters that are expert in certain necessary areas are working at a time. For example, if you ask about history, the router might activate the history expert and a few others, leaving the “cooking expert” dormant.
Pros:
- Efficiency at Scale: MoE models can achieve much higher intelligence for the same inference cost as a smaller dense model (because they are conditionally activated) Only a fraction of their total parameters are used per query, leading to faster response times for their immense knowledge base (So if you can’t fit the entire model into GPU VRAM, it “might” not become that slow if the active parameters are in VRAM and not system RAM)
- Specialization: Experts can become highly proficient in their specific domains, potentially leading to more nuanced and accurate responses within those areas.
Cons:
- Memory Hog: While fast in execution, MoE models require significantly more VRAM (Video RAM) to operate because all experts, even inactive ones, must be loaded into memory.
- Training Complexity: Training MoE models can be more complex and prone to instability compared to dense models, as the router needs to learn to distribute tasks effectively.
- Routing Errors: Occasionally, the router might misdirect a query, leading to a less optimal expert handling the task and potentially a lower-quality output.
Which Model for Which Task?
- Dense Models are excellent for general-purpose tasks where efficiency across a broad range of topics is important, especially when computational resources are limited. They are robust workhorses for many applications.
- MoE Models shine in scenarios requiring vast knowledge and extremely fast inference for very large models, such as advanced AI chatbots, complex code generation, or sophisticated research applications. They are built for scale and speed.
Which one is Best for Small VRAM GPUs
If you prioritize speed over raw intelligence (in other words, you don’t want to offload some of the model into system RAM) then dense models are almost always the better choice. Because MoE usually are massive in size and require more VRAM.
However, if you’re willing to sacrifice speed and offload some into RAM, MoE is the king of offloading. It makes 47B+ models usable on consumer hardware where a Dense equivalent would be frozen.
| Scenario | Model Type | Offloading | Speed | Experience |
| A | Small Dense (e.g., Llama 3 8B) | No (100% in VRAM) | ~100 tokens/sec | Instant, faster than reading speed |
| B | Big MoE (e.g., Mixtral 8x7B) | Yes | ~3–5 tokens/sec | Slow but tolerable |
| C | Big Dense (e.g., Llama 3 70B) | Yes | ~0.5 tokens/sec | Unusable |
Popular Examples
- Dense: Llama 2, Llama 3 (e.g., Llama 3 8B, Llama 3 70B), Falcon.
- MoE: Mixtral 8x7B, Grok-1, and it’s widely believed that models like GPT-4 leverage MoE architectures.
The choice between dense and MoE ultimately depends on your priorities. Understanding these differences empowers you to make informed decisions in the ever-expanding AI landscape.
That's all for this post. If you like it, check out our YouTube channel and our Twitter to stay tune for more dev tips and tutorials
